


Loading and querying a sample RDF graph
This example illustrates how to load and query data using OntoSQL tools. We created a new dataset named “cedar” which contains data and schema triples representing a small part of the Cedar team. Below, “RDF graph” and “Schema graph” represent two small fragments from this dataset. In general, one can load the data from two separate files, one with teh data and one with the ontology; however, in this example, both are in one file (which is also supported by OntoSQL). The only file format currently supported is .nt.
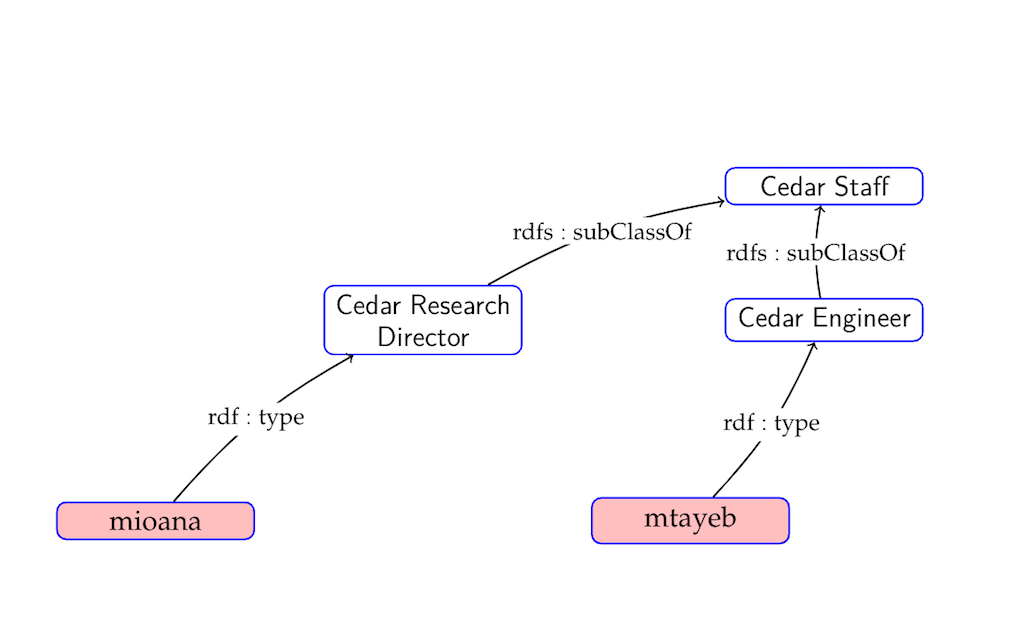
RDF graph

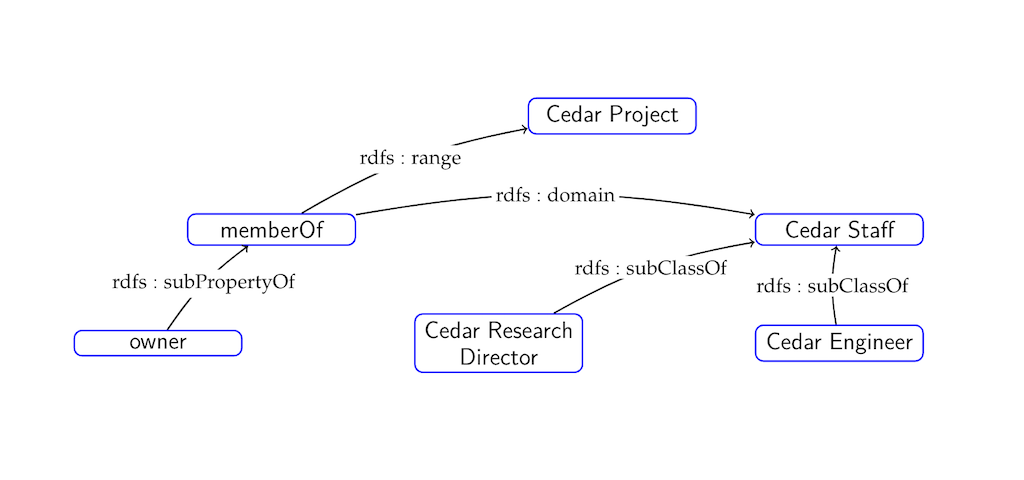
Schema graph
Loading the data
Download the data: RDF Data
Download RDFDB Tool: RDFDB
After extracting the “.tar.gz”, the working directory should contain:
- The RDFDB JAR file
- The conf directory which contains the default configuration file used by RDFDB
- Add the database credentials in the configuration file IOANA: WHICH? Ou alors c’est l’item en dessous? Reformuler
Next make sure to create a new PostgreSQL database and add your database credentials in the configuration file:
database.host = localhost database.port = 5432 database.name = dbrdftest database.user = dbuser database.password = dbpassword
Load your data into your DB
java -jar RDFDB-version.jar -input path_to_file_cedar.nt
It is possible to specify another property file using the parameter:
-pf the_path_of_a_new_property_file.prop
Chose the Storage layout
Using OntoSQL tools, two layouts can be used: triples table layout or Table per Role and Concept layout. From the configuration file, it is possible to specify which layout to use:
# Database (physical) storage layout. # Valid options: TRIPLES_TABLE, TABLE_PER_ROLE_AND_CONCEPT database.storage_layout = TRIPLES_TABLE #database.storage_layout = TABLE_PER_ROLE_AND_CONCEPT
Using the first layout (Triples table layout), only one table will be created into the database which contains all data and schema triples:

Using the second layout, RDFDB creates from data triples one table for each concept and role:
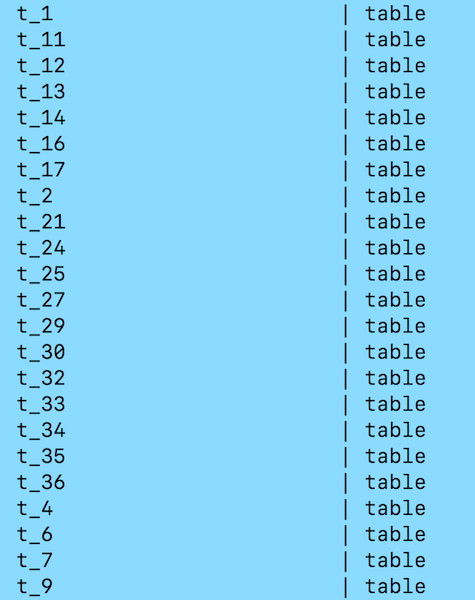
In the last figure, t_33 is the table for the concept (type) “cedar staff”. The table contains all cedar staff resources such as: “mioana” and “mtayeb”.
Querying the data
Download QuerySession Tool: QuerySession
After extracting the “.tar.gz”, the working directory should contain:
- The QuerySession JAR file
- The conf directory which contains the default configuration file used by QuerySession.
- The queries directory which contains queries of the example below.
As in loading process, you need to add Database credentials to the configuration file. It is also possible to specify what layout model you want to use into the configuration file.
From any Conjunctive query, the tool can provides four (4) query answering strategies:
- Through saturation (SAT)
- Through reformulation, in particular in one of the following three methods:
- through semi-conjunctive queries (SCQ)
- through a union of conjunctive queries (UCQ)
- through a join of unions of conjunctive queries (JUCQ)
Translating and/or executing queries
Two options are mandatory:
- -type: select the query answering strategy among sat, scq, ucq or jucq according to the four types cited above.
- -qr: the path of file contained queries to be translated and/or executed.
For instance, to use saturation, call:
java -jar QuerySession-version.jar -type sat -qr the_path_of_the_queries_file
Other options can be added:
- -isHybrid: translating the query using the tcp layout. Triples table for unspecified and generic triples, and cp layout for other triples.
- -isDirect: direct translation for cp layout only.
- -TTranslate: triples table translation after an ucq reformulation.
- -maxQ: for the maximum numbers of queries to be translated and evaluated from the file (if you want to restrict to just the first few queries)
- -pSQL: to print the SQL query.
- -pPlan: to print the logical algebraic plan that will be used to answer the query.
Sample queries
- Conjunctive query: list all Cedar Staff
![]()
- SQL query
- If the triples table layout was used:
SELECT pt0.s AS att_x FROM encoded_saturated_triples AS pt0 WHERE pt0.p='28' AND pt0.o='33'
-
- If the Table per Role and Concept layout was used:
SELECT tt_1.s AS att_x FROM t_33 AS tt_1
-
-
- Results (regardless of the layout):
![]()